Direct Steady-State Solver
Direct steady-state solver
The direct steady-state solver (dss) solves for instant-of-time variables with 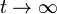 , using a numerically stable version of LU decomposition[1]. It does so by solving the system of equations given by
, using a numerically stable version of LU decomposition[1]. It does so by solving the system of equations given by 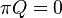 , with the additional constraint that the sum of all elements in the vector
, with the additional constraint that the sum of all elements in the vector  must equal one. is the state occupancy probability vector, and
must equal one. is the state occupancy probability vector, and 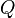 is the generator matrix. The generator matrix is obtained from the SAN through use of the state space generator (see Section 2.2). The solver uses two methods to reduce the fill-ins (non-zero elements) of the matrix during solution: (1) the improved generalized Markowitz strategy, which selects a next pivot element based on a heuristic that can reduce fill-in, and (2) a technique that sets elements below some threshold (which is tunable, see the options below) to zero during the execution of the solution algorithm[1]. If the problem is not too large, the solver then uses iterative refinement to reach a correct final solution. The solver calculates the mean and variance for each performability variable. The means and variances are recorded in textual form in the output file. <xr id="fig:dssSolver" /> shows the editor for the direct steady-state solver and its available options and adjustable parameters.
is the generator matrix. The generator matrix is obtained from the SAN through use of the state space generator (see Section 2.2). The solver uses two methods to reduce the fill-ins (non-zero elements) of the matrix during solution: (1) the improved generalized Markowitz strategy, which selects a next pivot element based on a heuristic that can reduce fill-in, and (2) a technique that sets elements below some threshold (which is tunable, see the options below) to zero during the execution of the solution algorithm[1]. If the problem is not too large, the solver then uses iterative refinement to reach a correct final solution. The solver calculates the mean and variance for each performability variable. The means and variances are recorded in textual form in the output file. <xr id="fig:dssSolver" /> shows the editor for the direct steady-state solver and its available options and adjustable parameters.
<figure id="fig:dssSolver">

The options are as follows:
- The Rows is an integer representing the number of rows to search for a pivot. Zero is the default, meaning pivoting is turned off by default. A value of 2 or 3 is recommended[1].
- The Stability is a short integer representing the “grace” factor by which elements may become candidates for pivots. 0 is the default, meaning pivoting is turned off. A stability factor between 4 and 16 is recommended in the literature; see [1], for example.
- The Tolerance is a double that, when multiplied by the smallest matrix element, is the threshold at which elements will be dropped in the LU decomposition. 0.0 is the default, which implies that no dropping takes place. In general, it is recommended[1] that the drop tolerance be chosen to be two to five orders of magnitude smaller than the smallest matrix element, i.e., choose the Tolerance between 10-2 and 10-5.
- Verbosity (
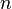 ) sets the trace level for intermediate output. The default is no intermediate output. If
) sets the trace level for intermediate output. The default is no intermediate output. If 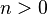 , then the message “completed column number n” is printed after every iterations during the LU decomposition computation, forward substitution, backward substitution, and iterative refinement.
, then the message “completed column number n” is printed after every iterations during the LU decomposition computation, forward substitution, backward substitution, and iterative refinement.
- Verbosity (
The output file contains the means and variances of the performability variables. It also records the following information:
- whether iterative refinement was used,
- the drop tolerance,
- the number of non-zero elements in the original matrix,
- the number of non-zero elements in the factorized matrix,
- if iterative refinement was used, the maximum difference between the cells in the
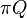 and zero vectors; if iterative refinement was not used, the relative error,
and zero vectors; if iterative refinement was not used, the relative error,
- if iterative refinement was used, the maximum difference between the cells in the
- the number of correct decimal digits in the state probabilities,
- the number of zeros in the factorized matrix,
- the number of elements dropped,
- the number of new pivots selected.
Pitfalls and Hints
- dss can be used if the steady-state distribution of the Markov model consists of a single class of recurrent non-null states. For instance, dss cannot be applied to a model with multiple absorbing states. If it is, the message “invmnorm: zero diagonal element” will appear and the performance variable will take the NaN (Not a Number) value. To find out whether the model has absorbing states, apply the Flag Absorbing States option in the state space generator.
- dss is effective when relatively small models are considered, because in the process of computing the steady-state probabilities, the original transition matrix is transformed into a matrix with many non-zero elements. Sparse matrix methods, which use the fact that elements equal to 0 do not have to be stored, can then no longer be profitably applied. This is known as the fill-in problem. Especially when large models are considered, fill-ins can become a serious bottleneck, because the order of non-zero elements is, in general, quadratic in the size of the state space. Consequently, dss cannot be used to solve models having state spaces that are larger than several thousand states. Note that the setting of the drop tolerance may be used to partially overcome fill-ins of the matrix.
- The CPU time required by dss also increases in the number of states (with a power of 3). The iterative solver iss often becomes faster than the direct solver dss when the state space size increases.